
TSDB时序数据库
什么是时序数据库?
指一串按照时间维度索引的数据,实际上包含三部分数据:
- 主体
- 时间点
- 测量值
什么是时序数据?
特点
- 数据模式: 时序数据随时间增长,相同维度重复取值,指标平滑变化,这点从上面的Network表的数据变化可以看出。
- 写入: 持续高并发写入,无更新操作
- 查询: 按不同维度对指标进行统计分析,且存在明显的冷热数据,一般只会频繁查询近期数据。
数学模型
- measuremet:度量的数据集(指目前这个时序表存储的是什么数据类似table)
- point:指代某一个时序数据的一条记录,类似row
- timestamp:指采集到的数据的某一个时序数据的时间点
- tag:维度列,表示数据是谁产生的,不随着时间变化而变化
- field:指标列,表示数据的测量值,随着时间变动
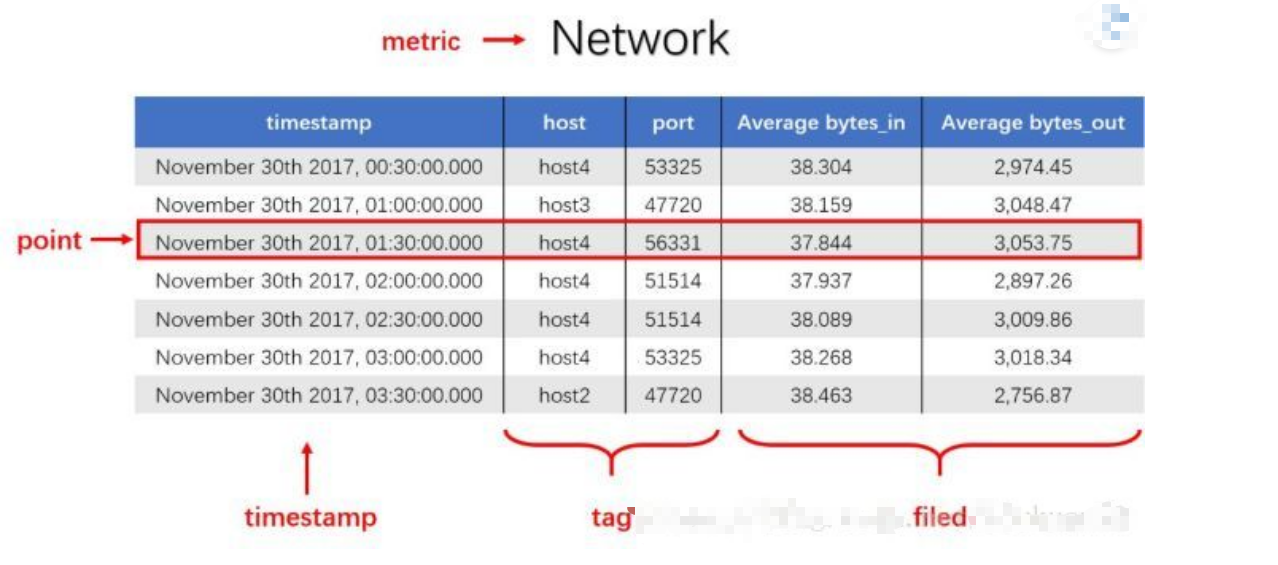
图中数据
host:port表示这组数据是由哪个机器产生的,前面时间戳代表不同时间阶段的数据变化,而后面的bytes_in && bytes_out可以反应这一阶段内服务器读入与读取的压力增大。
存储结构
传统结构
- Mysql
- 存储成本大,对于时序数据压缩较小,需要大量机器资源。
- 维护成本高,需要人工进行分库分表
- 单机吞吐量不高,无法满足时序数据千万写入压力
- 查询性能低,海量数据聚合分析慢
- Hadoop、Spark
- 由于离线批处理系统,对数据产生、分析、生成消耗时间太大
- 查询性能低下,不能良好利用索引信息,需要使用
MapReduce任务(Hadoop获取数据的一种方式 提交任务->聚合计算->查询任务状态->获取结果)
时序数据库
概述
需要解决的问题:
- 时序数据的大量写入(每秒千万上亿数据点)
- 时序数据的快速读写(秒级亿级别数据聚合分析)
解决:
- 存储成本:利用时间递增、维度重复、指标平滑变化的特性,合理选择编码压缩算法,提高数据压缩比,通过预降精度,对历史数据做聚合,节省存储空间。
- 高并发写入:批量写入数据,降低网络开销,定期由内存 -> dump -> 磁盘
- 低查询延时,高查询并发:优化常见的查询模式,通过索引等技术降低查询延时,通过缓存、routing等技术提高查询并发。
存储原理
传统数据库大多采用Btree进行存储,这种自带索引的方式可以大大减少查询与顺序插入过程中磁盘的寻道次数,但是时序数据大多都是随机写入,因此对于90%以上场景的写入Btree不够合理。目前主要采用LSM tree进行替换,其包括内存结构和磁盘文件两部分。
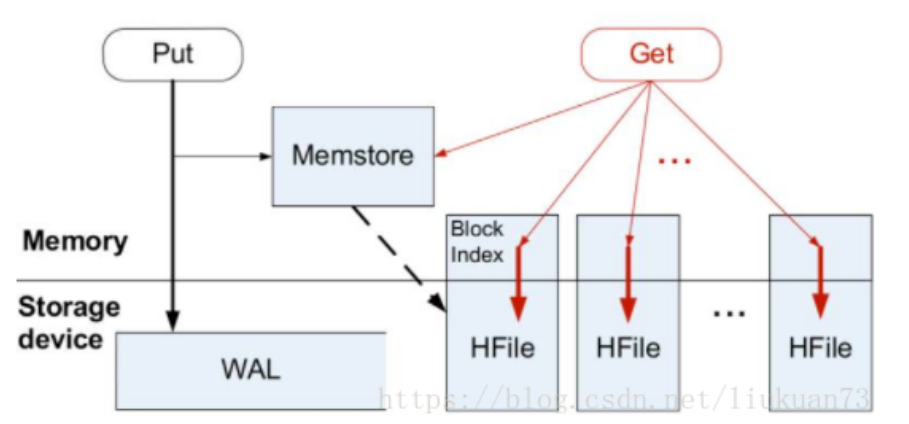
数据更新与写入时,先写入memstore内存中,并且为了防止丢失数据也会先写道wal文件中,之后根据内存文件大小定期写入hfile中进行持久化,当hfile文件大小增多时进行合并。但是可能会导致一个key的信息可能存在多个hfile中,所以会降低查询性能,需要对其进行优化和处理(可以采用布隆过滤器进行处理)
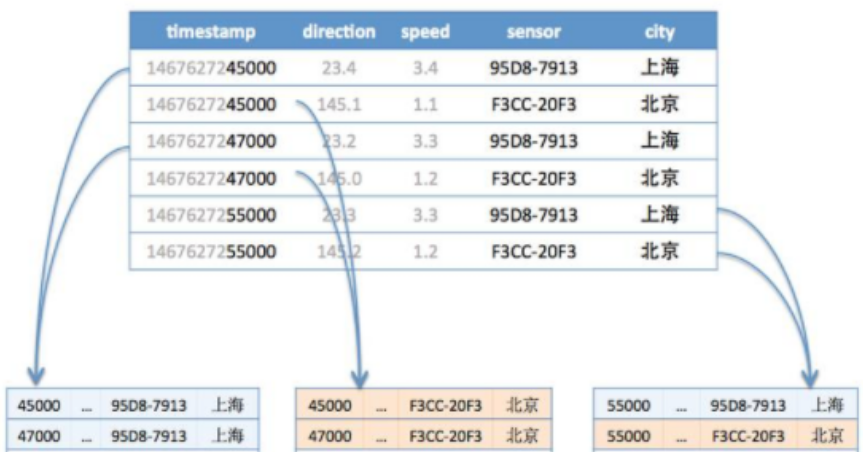
分片存储
由于时序数据存储的是一个时间point中发送产生的数据,因此可以按照其measurement tags进行分片存储,将这个分片防止于一台机器上的一片连续空间,再根据不同的timestamp进行划分,存储于不同的机器上,这样就可以支持大范围时间区间的查询。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 Bai's Blog!