
Kafka Partitioning - Topic分区
Kafka是一个分布式系统,如果一个Topic只能存在一个Node上面其实会影响Kafka的分布式扩展能力,这样Topic实际上不会超过集群中最大的Niode存储大小,当然Kafka也可以做到这样的设计。但是实际上每一个Node不会获得有太多的消息数据量以及消息读写量,因此Kafka允许我们进行Topoic数据分区。
每一个Topic都可以进行分区,并且每个分区都可以存储于不同的Kafka节点上

消息分发:消息可以存在一个Key或者不存在一个Key
- 不存在Key:消息被轮询分发到每个分区上
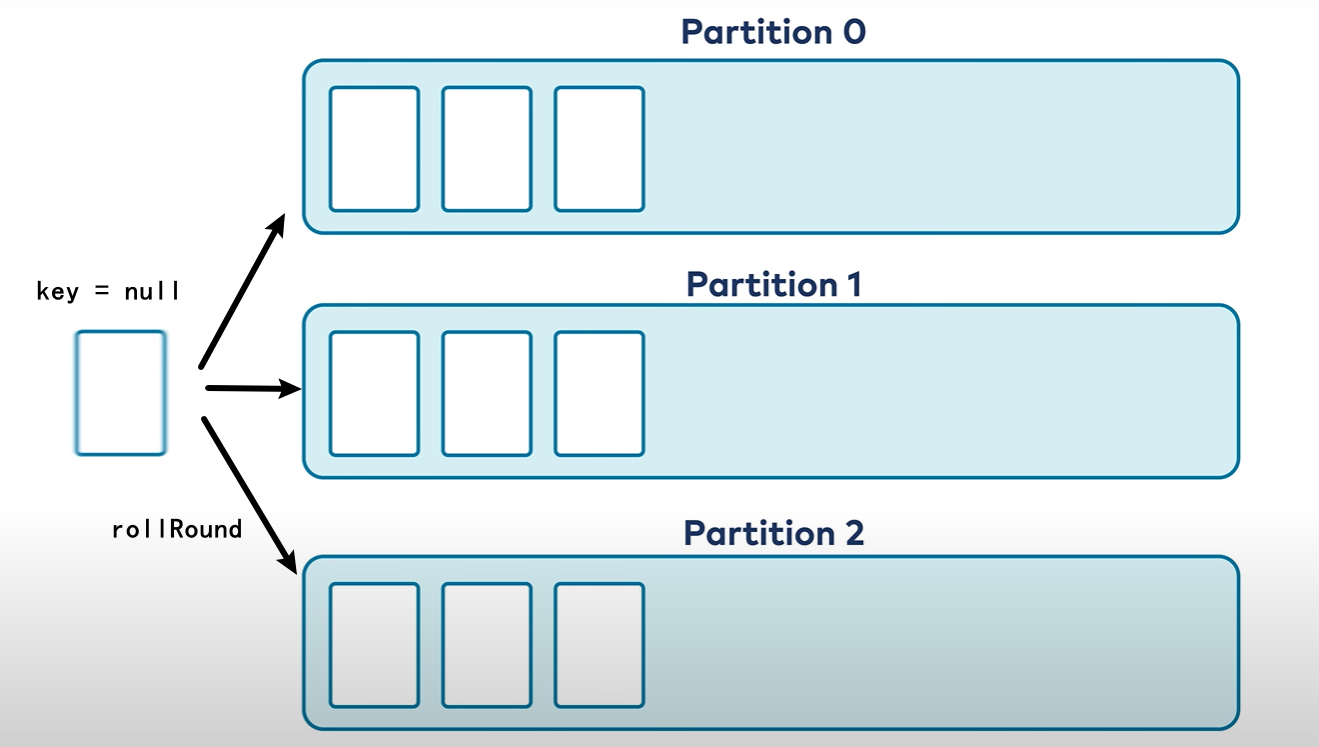
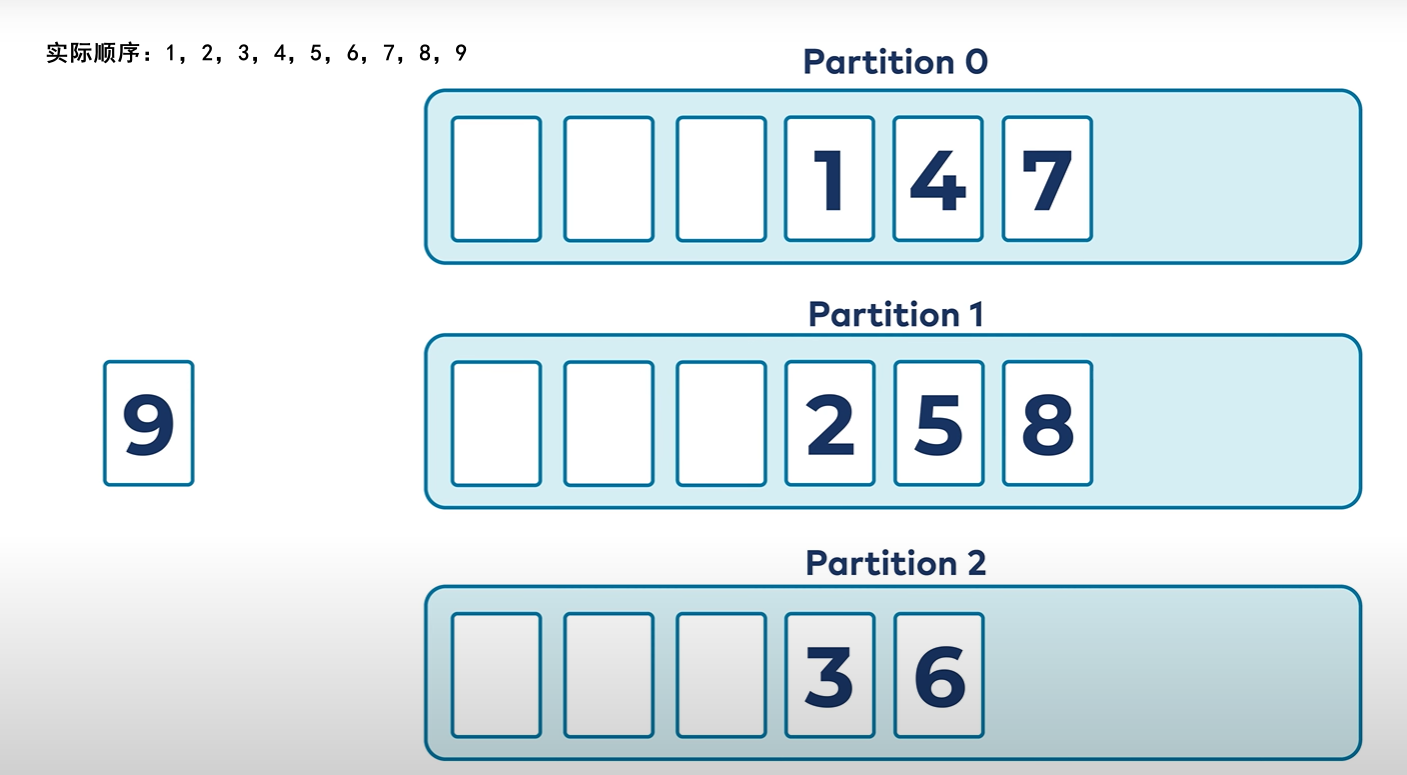
但是不能保证真正的消息有序,每个分区看起来实际只是一种时间上的有序,不能反映真实消息有序性。
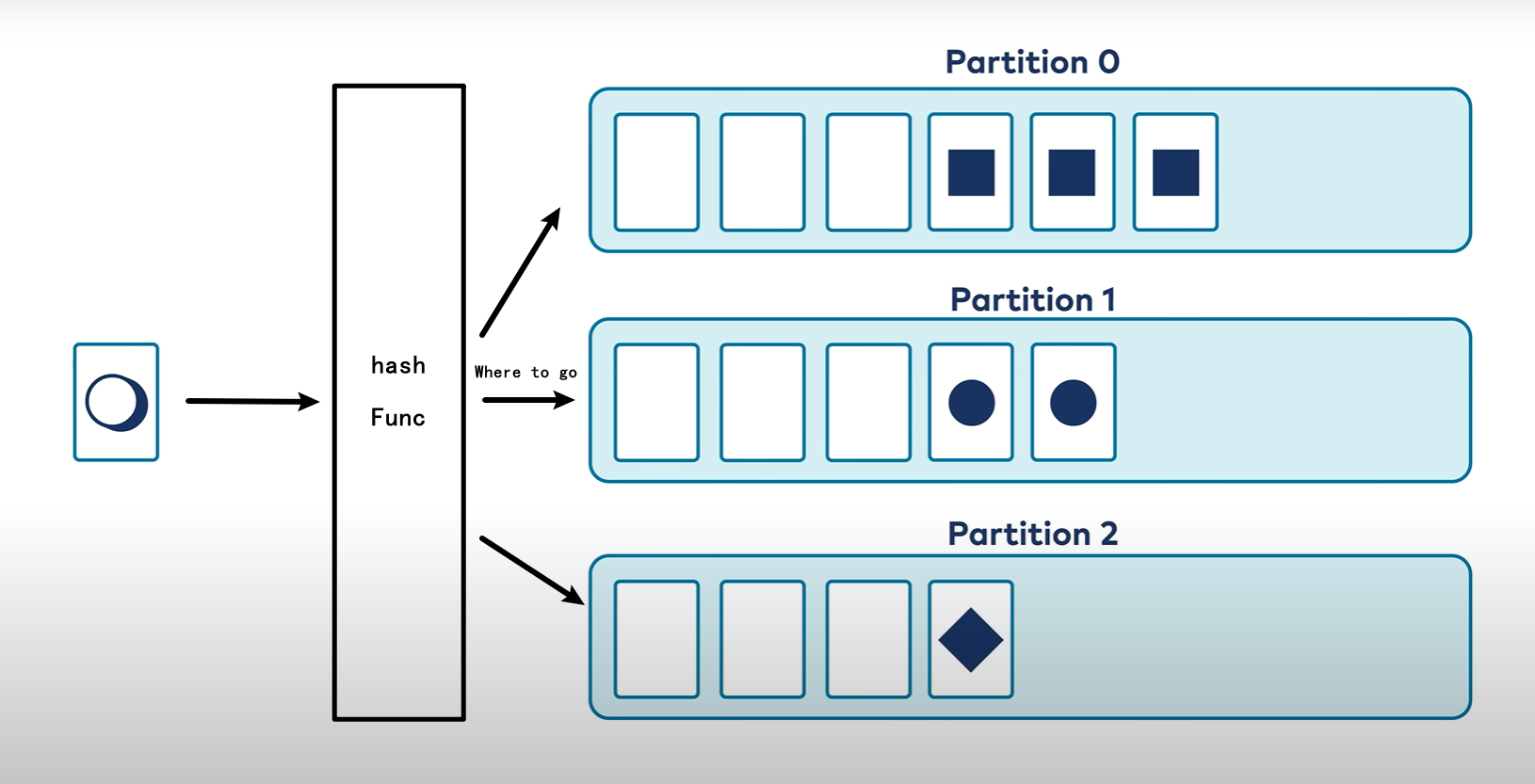
- 存在Key:使用Key来决定分发到那个分区上面(Hash Func)可以保证相同Key始终存在于一个分区
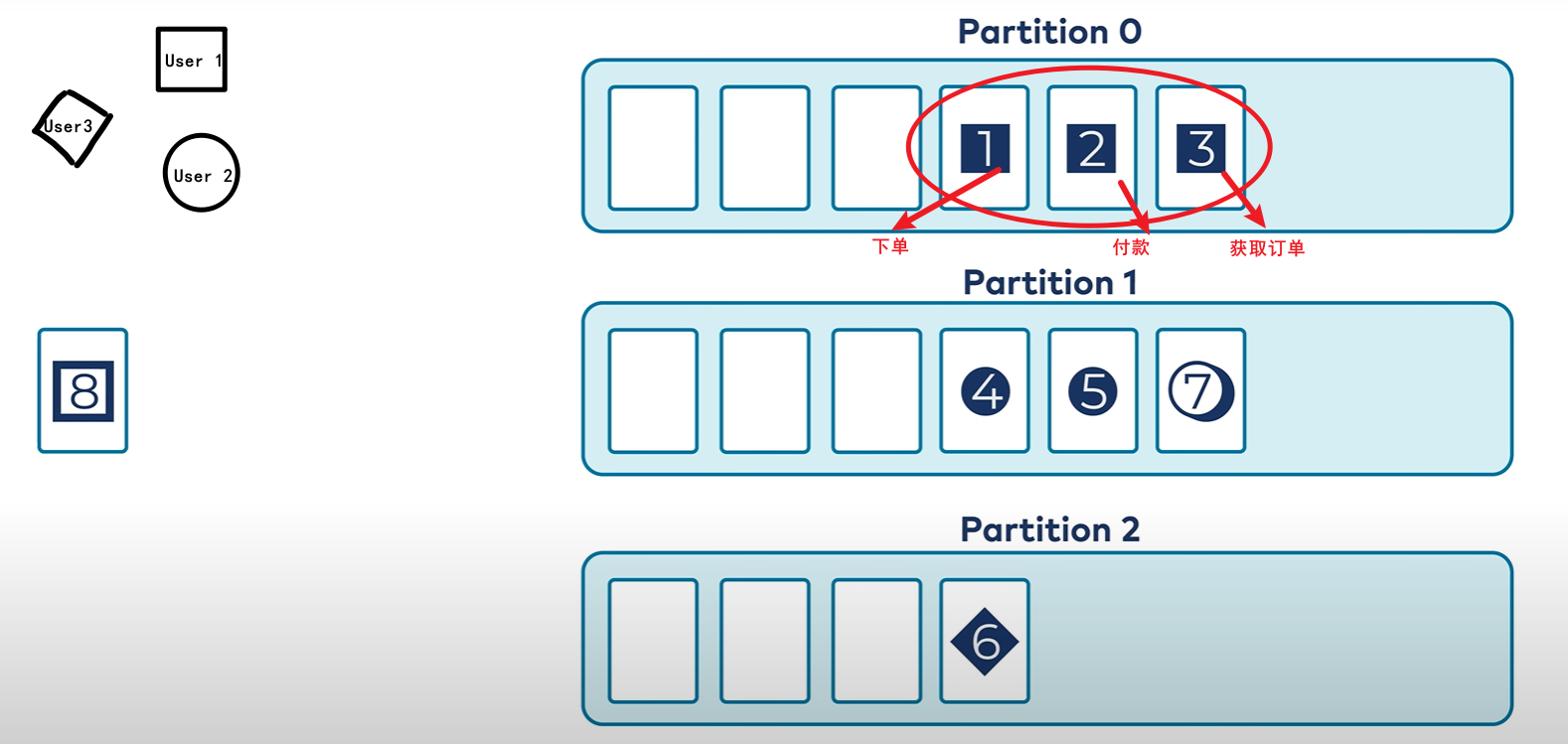
需要保证每个相同Key中不同事件是有序的,那么可以使用Key,因为使用了Key,kafka会将这个Key发送到一个Hash的分区上,而在这个分区中是保证有序的。(比如一个用户的Key是12,那么会保证12永远被分发到一个分区上面,那么对于这个客户而言 下单 -> 付款 -> 获取订单 可以保证这个三个事件消息到达顺序,那么消费的时候也就是有序的)
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 Bai's Blog!