
Location匹配规则
location的两种语法
- 多个正则location直接按书写顺序匹配,成功后就不会继续往后面匹配
- 普通(非正则)location会一直往下,直到找到匹配度最高的(最大前缀匹配)
- 当普通location与正则location同时存在,如果正则匹配成功,则不会再执行普通匹配
- 所有类型location存在时,“=”匹配 > “^~”匹配 > 正则匹配 > 普通(最大前缀匹配)
- 第一种语法分为3个部分, 分别是:
location关键字+@name别名(name是自己取的名字)+如何处理, 这个语法很简单, 就是做内部跳转, 这里不讨论了.
location @name { ... } |
- 第二种语法分为4个部分, 分别是:
location关键字+匹配方式符号(可省略)+匹配规则+如何处理, 这个最复杂也是最常用, 我们只讨论这个.
location [ = | ~ | ~* | ^~ ] uri { ... } |
普通匹配和正则匹配
这个语法的难点全部集中在[ = | ~ | ~* | ^~ ]这里, 只要搞懂这个就能正确使用location.[ = | ~ | ~* | ^~ ]分为两种匹配模式, 分别是普通匹配和正则匹配.
普通匹配概述
=: 这代表精准匹配全路径, 命中它后直接返回, 不再进行后续匹配, 优先级最高.^~: 这代表精准匹配开头, 命中开头后直接返回, 不再进行后续匹配, 优先级第二.- 无匹配方式符号 : 这代表通用性匹配, 命中后还会继续后续匹配, 最后选取路径最长的匹配, 并储存起来, 优先级第四.
普通匹配举例
#这是精准匹配, 只有请求路径完全匹配`/index.html`才会命中它 |
正则匹配概述
~: 这是区分大小写的正则匹配, 命中后则不进行后续匹配, 立即返回, 优先级第三.- *~: 不区分大小写的正则匹配, 命中后则不进行后续匹配, 立即返回, 优先级第三.
这里有个很重要点点, 也就是正则匹配中~和*~优先级一样, 它们按照从上到下的顺序进行匹配, 最先命中的立即返回, 后续的不会进行匹配, 所以精细的正则匹配规则往前放, 通用的正则匹配规则往后放.
正则匹配举例
#区分大小写的正则匹配, 如果路径包含 /image/ 则立即返回, 注意这里并不需要开头命中, 因为这是正则表达式 |
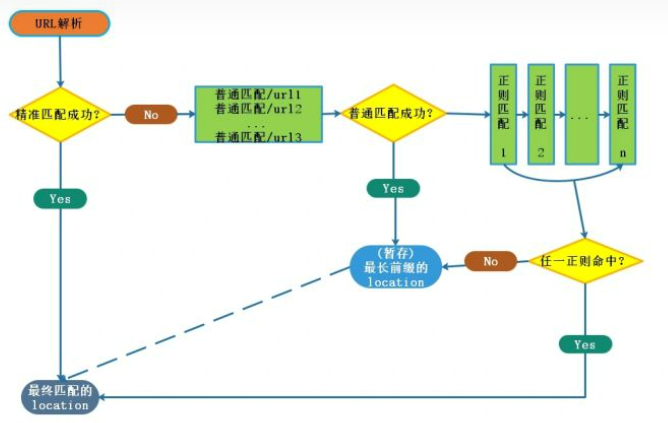
location如何匹配?
- 先进行普通匹配中的
精准匹配, 如果命中了立马返回. - 然后进行普通匹配中的
精准开头匹配, 如果命中则立马返回. - 进行普通匹配中的
无匹配符号匹配, 如果命中继续匹配, 知道普通匹配全部完成, 并保存路径最长的匹配. - 由上自下进行正则匹配, 如果命中立即返回.
- 如果正则匹配全部失败, 则返回普通匹配中存放的匹配.
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 Bai's Blog!